Group: HADA
Dataset: exams
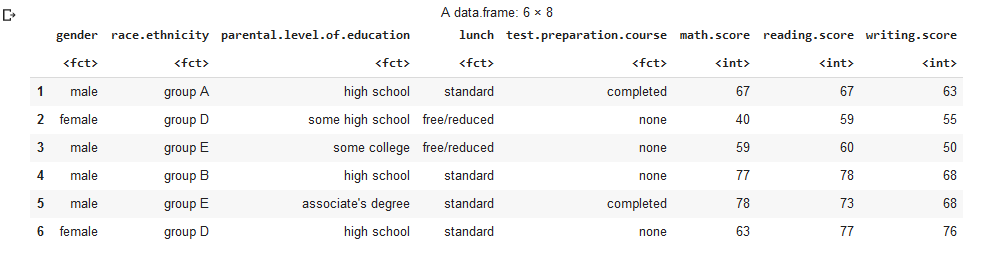
The data we working out are exams.csv that contains score data for completed tests.
Understanding the data:
From data exploration mode, we can define that :
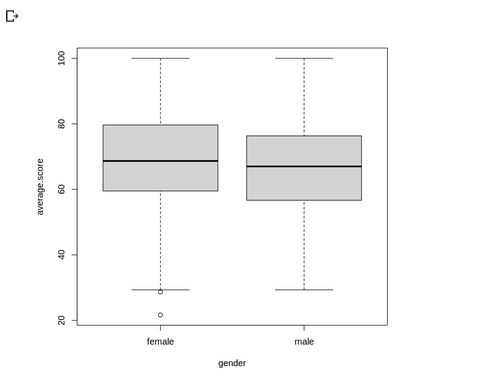
• gender : gender of the student
• race.ethnicity : group the student ethnicity as Group A to group F
• parental.level.of.education : define the parent level of education of students
• lunch : The type of lunch take by the student
• test.preparation.course : The status of test prepartion course of the student
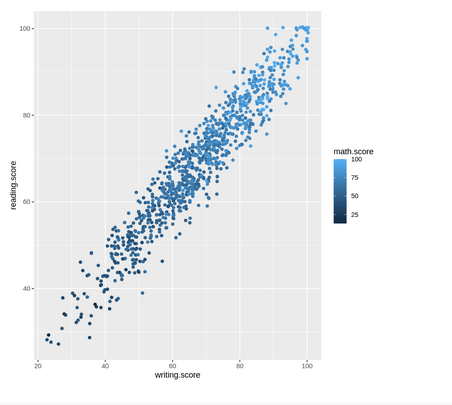
• math.score : The mathematic test score of the student
• reading.score : The reading test score of the student
• writing.score : The writing test score of the student
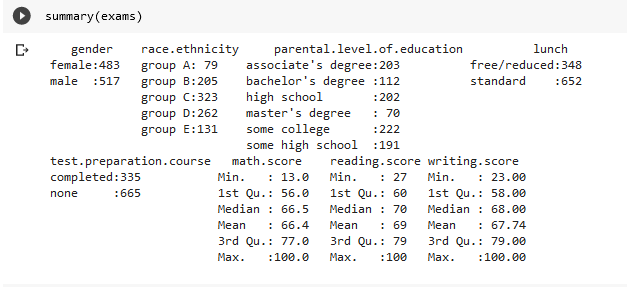
Data Cleansing & Analysis:
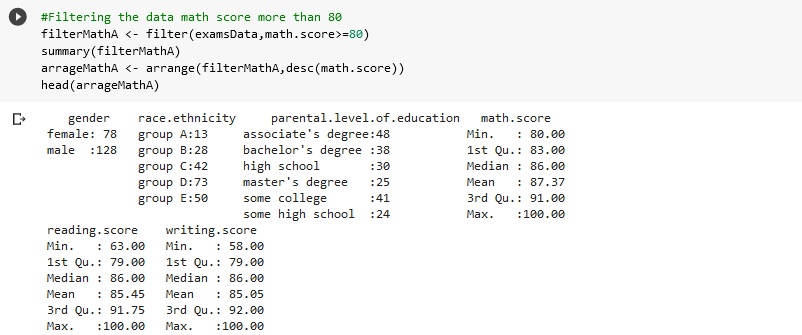
We filter the data for math.score that more than 80
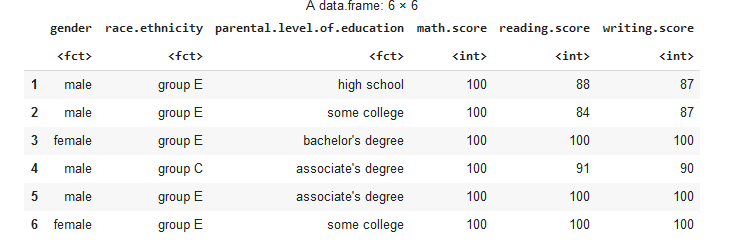
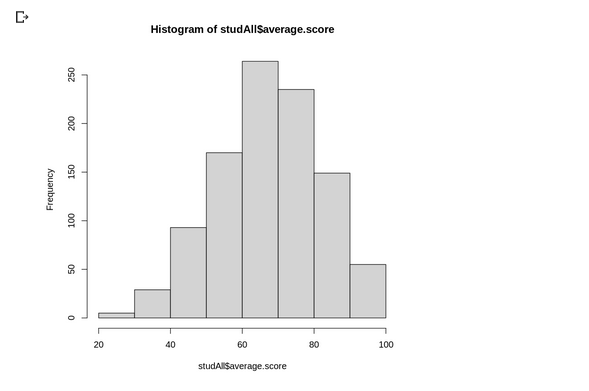
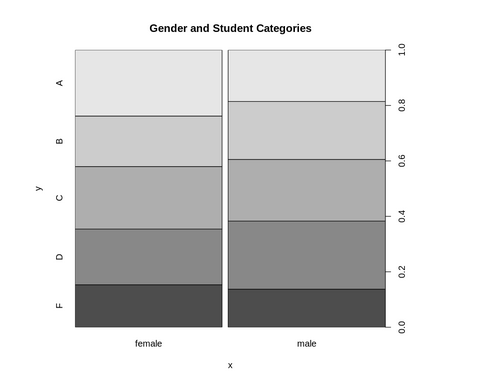
next, we create new coloumn of average student and their categories based on average score:
Machine Learning:
After analyze and explore the data we visualize the data :