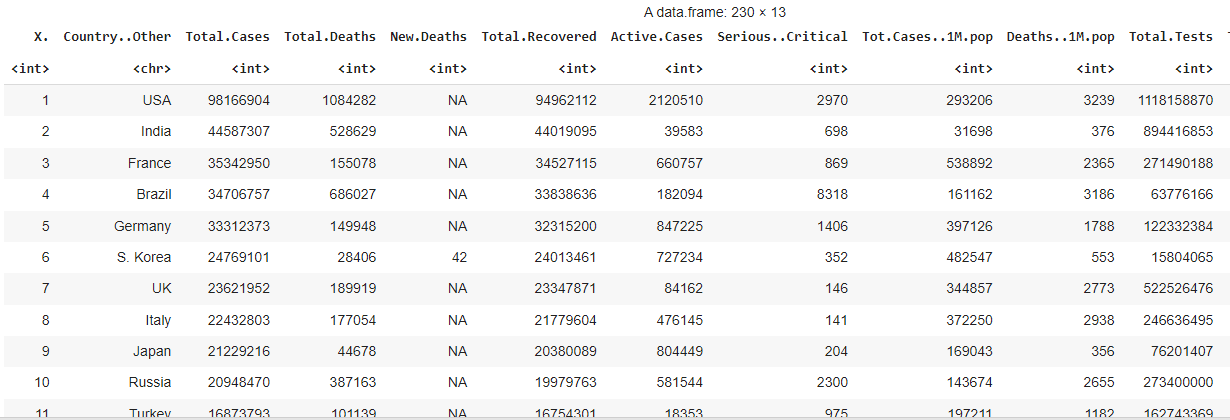
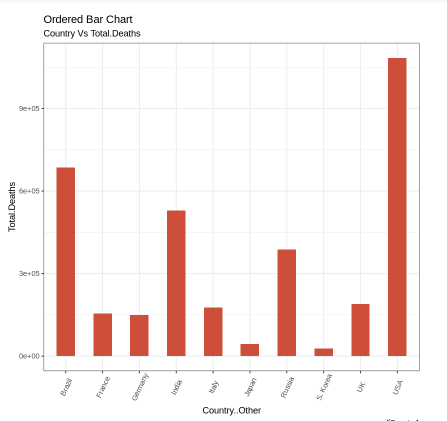
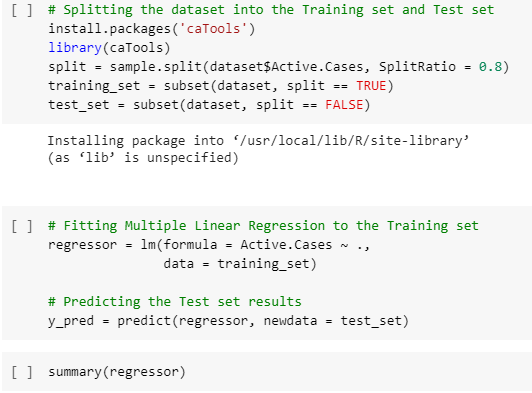
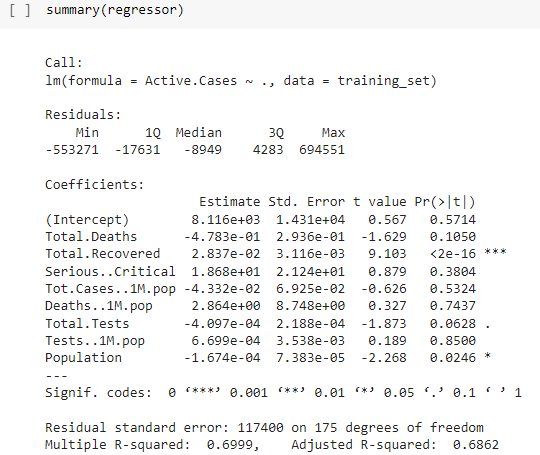
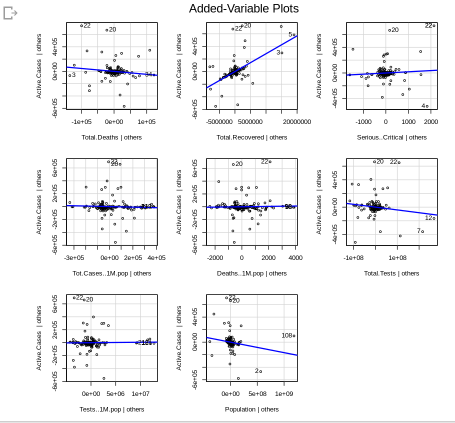
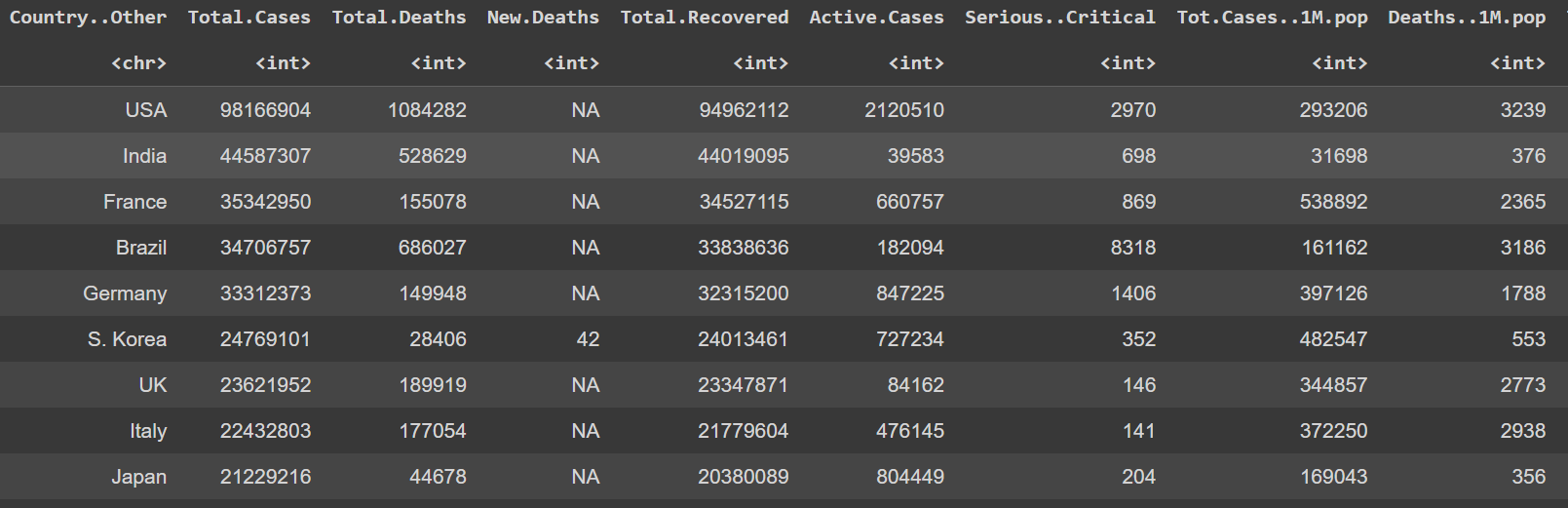
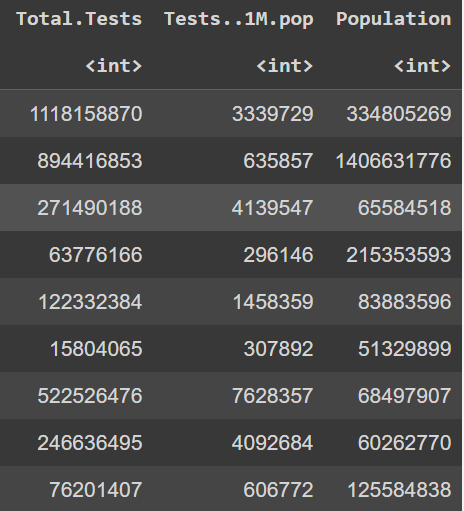
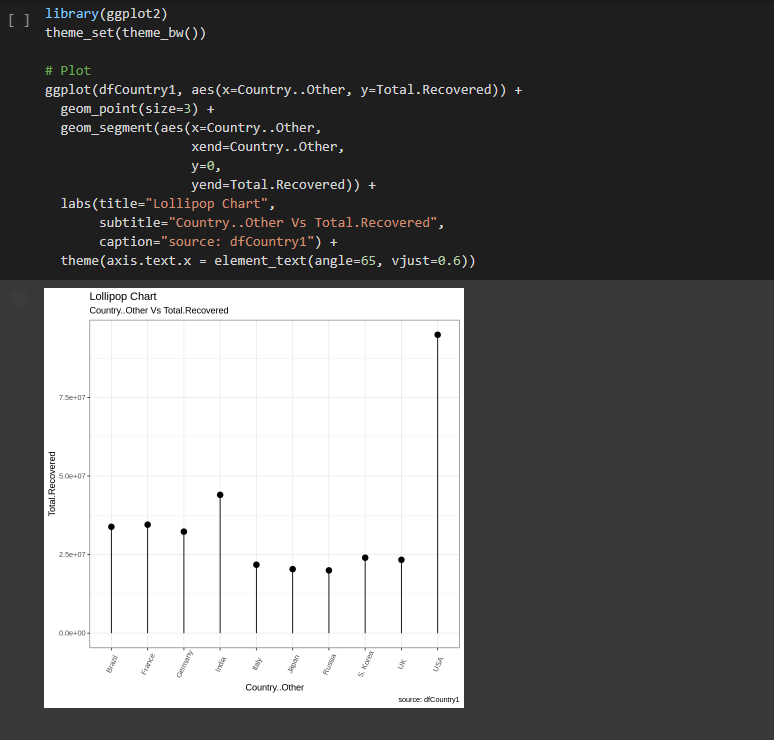
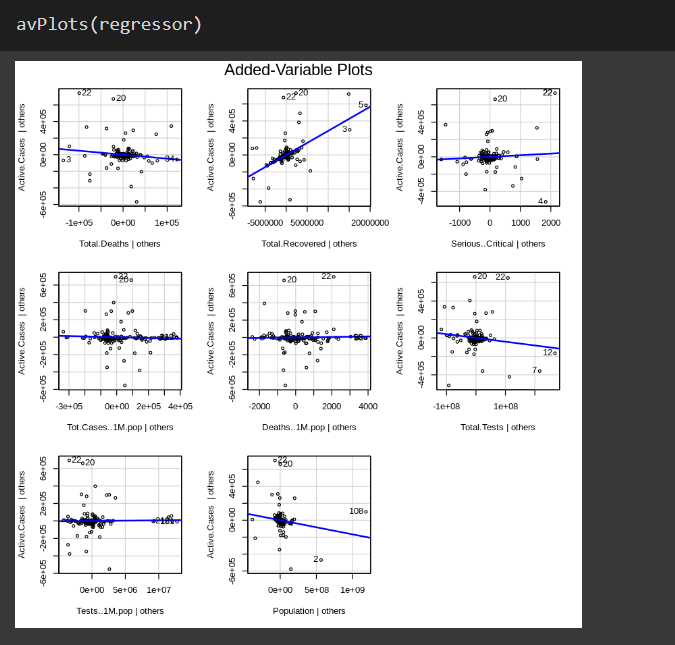
Dataset : full_data.csv
1. Understanding the data
As no description was provided following the dataset, we begin with establishing our general understanding about the dataset and identifying the input and output variables:-
We pay attention to:
-
number of columns and the names -> what the data is about and how many variables we going to analyze (prep our mind with the degree of complexity we are going to handle 🥶.)
-
data type of each columns -> which columns should be the input variables, and which should be the target output. Also give an idea about what kind of prediction should be performed..is that regression or classification problem?
-
number of rows -> how many samples we had
From this undertaking:
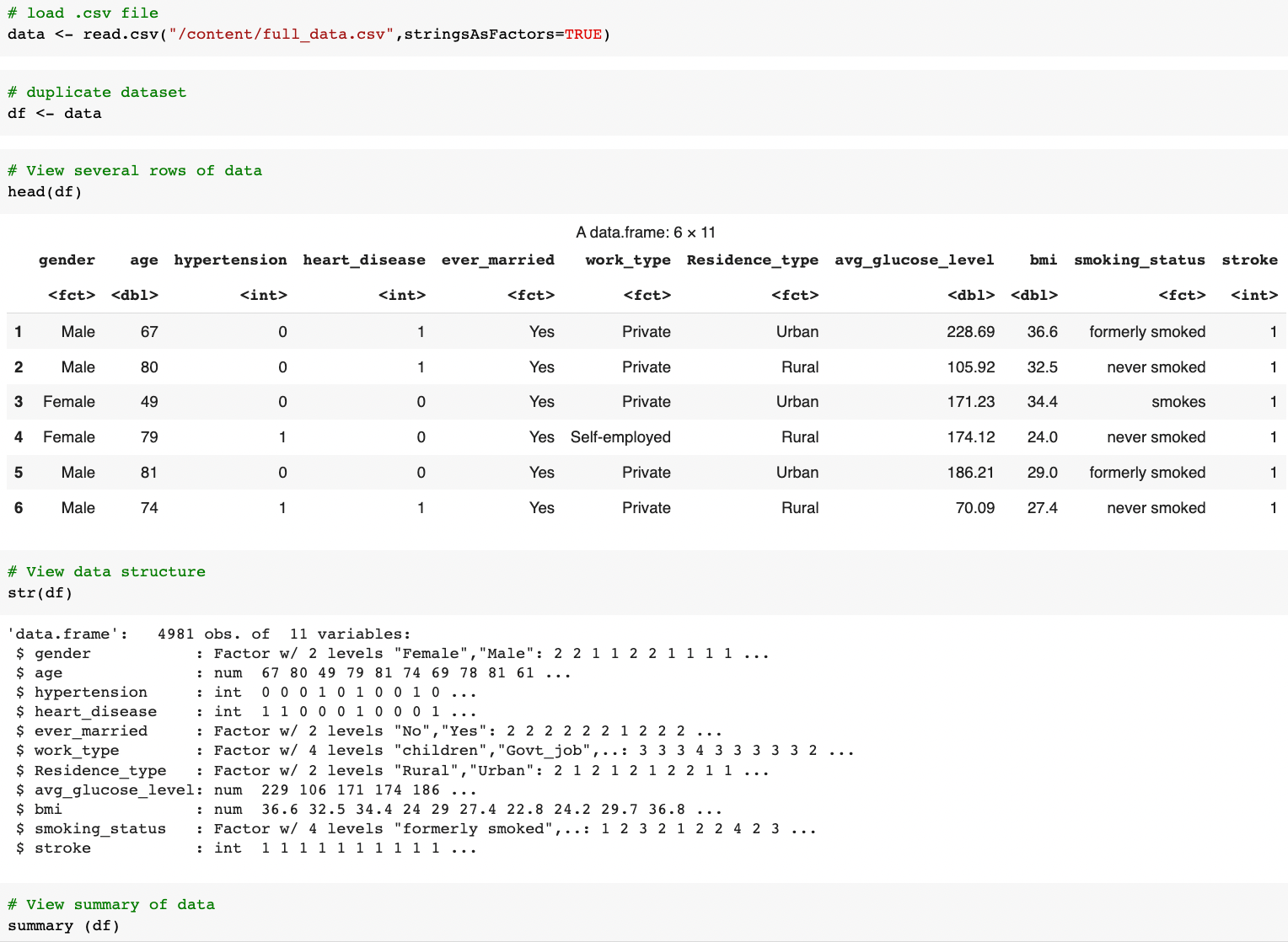
We learned that this dataset has 4981 rows and 11 columns labeled as
gender, age, hypertension,heart_disease, ever_married, work_type, Residence_type, avg_glucose_level, bmi, smoking_status, stroke.
-
Thus, we assumed this dataset was from a 'health' sector and was sampled from 4981 patients.
-
We deduced that this dataset collects 10 parameters (input variables) on patients with and without stroke (1 output variable or target).
-
As such, we going to do a stroke prediction based on the classification problem.
2. Data Cleaning
At this stage, we aimed to ensure our data is consistent across the dataset:
-
no missing data
-
appropriate data type and values (E.g: age, avg_glucose_level,bmi shouldn't have negative values )
-
consistent format (E.g: gender should be either 'Male' or 'Female' only, not a mixture of other representations 'F', 'male', etc)
self-explain label
-
relevant (no unique values like ID number, names, etc)
The given dataset is actually pretty clean and met the above-mentioned criteria. The only amendment we did was changing the data type of hypertension, heart_disease, and stroke from integer to factor as these variables tell whether the patient has the illness or not (yes/no).

3. Exploratory Data Analysis
This stage aims to provide the descriptive (what happened) and diagnostic (why it happened) analysis. We approach the EDA by categorical data, numerical data, and combination of both to understand the relationship:
Categorical data
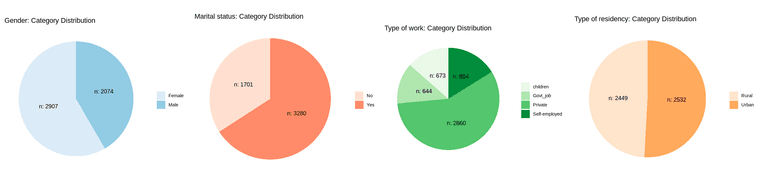
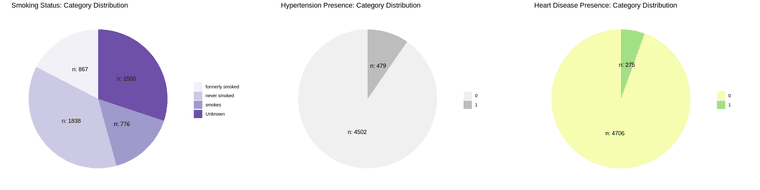
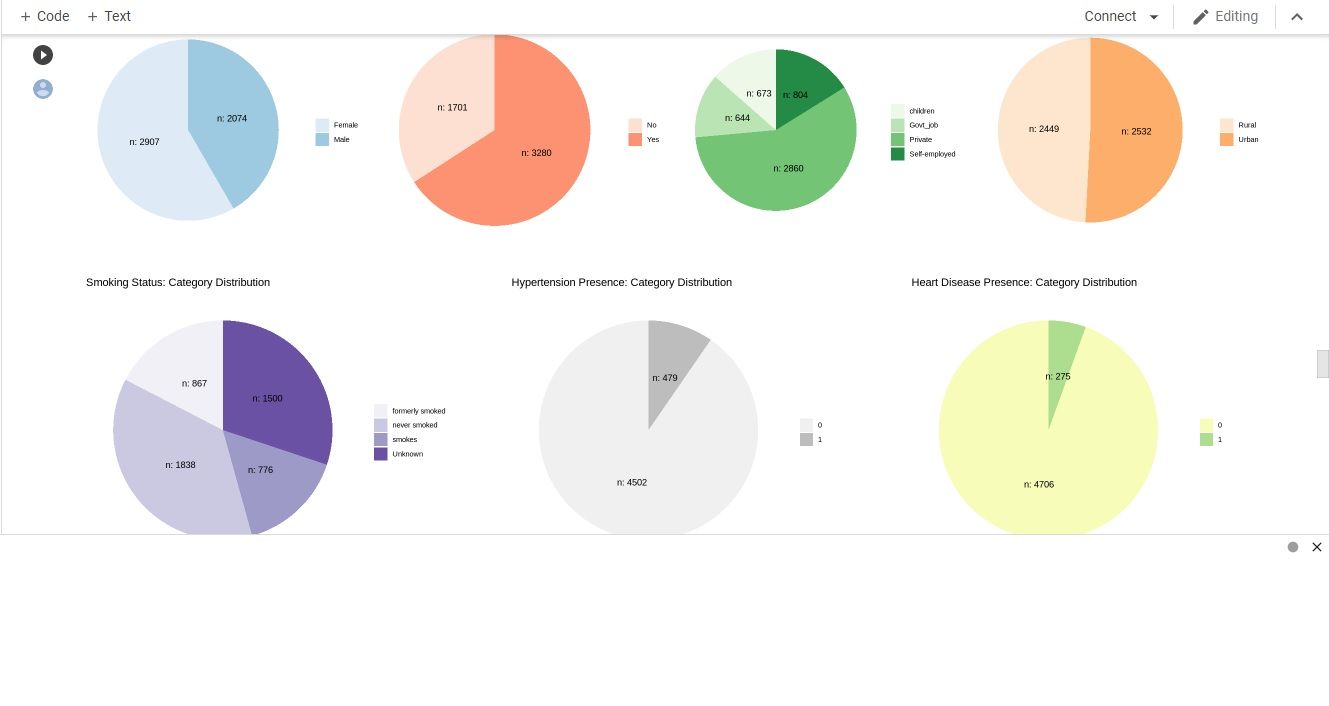
Distribution of samples by each category:
-
most of the sampled patients are married, working at private sector, has neither hypertension nor heart disease.
-
the sampled patients are almost equally distributed by gender(male or female) and type of residence (rural or urban)
-
majority of the sampled patients are non-smokers (either never smoked or formerly smoked).
Numerical data
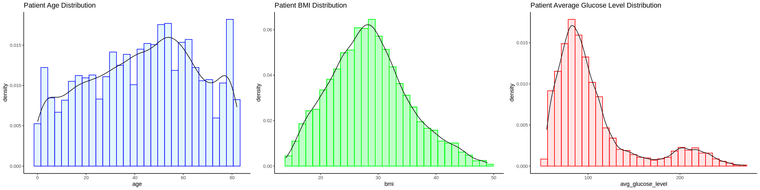
Range of each variable:
-
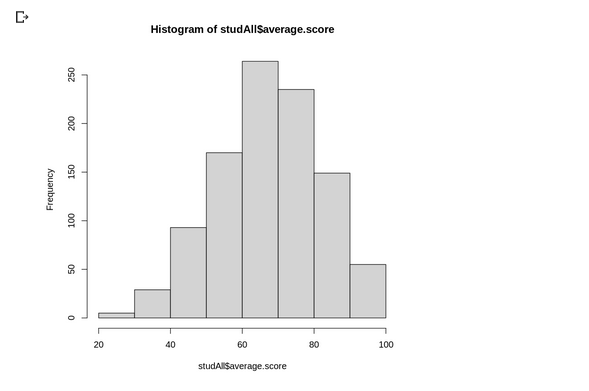
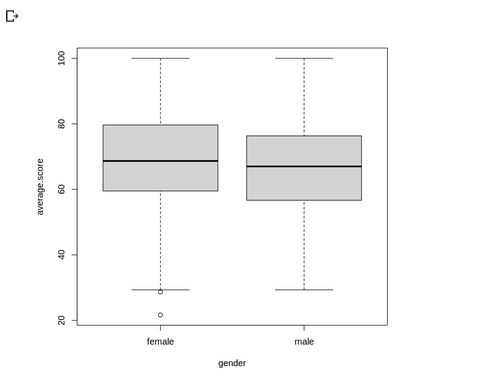
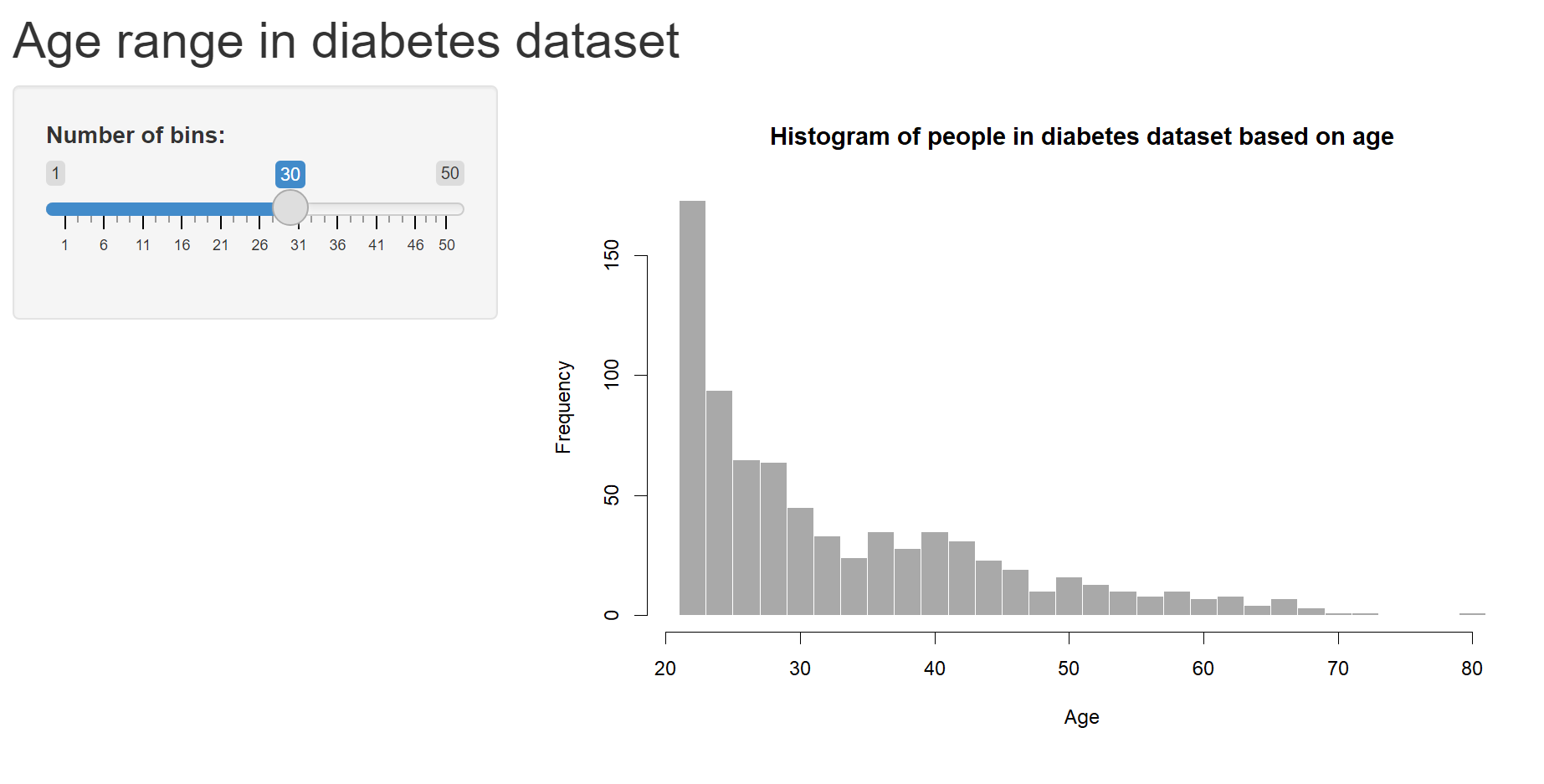
The age of sampled population of patients are 0<aged< 85, with most are between 40-60 and ~ 80 years old.
-
The sampled patient bmi are normally distributed with center ~30 (most of the patients have weight issue).
-
The glucose level skewed to the right with obvious 2 peaks at ~100 and ~200 glucose level (most of the patients have high blood sugar).
Understanding the relationship

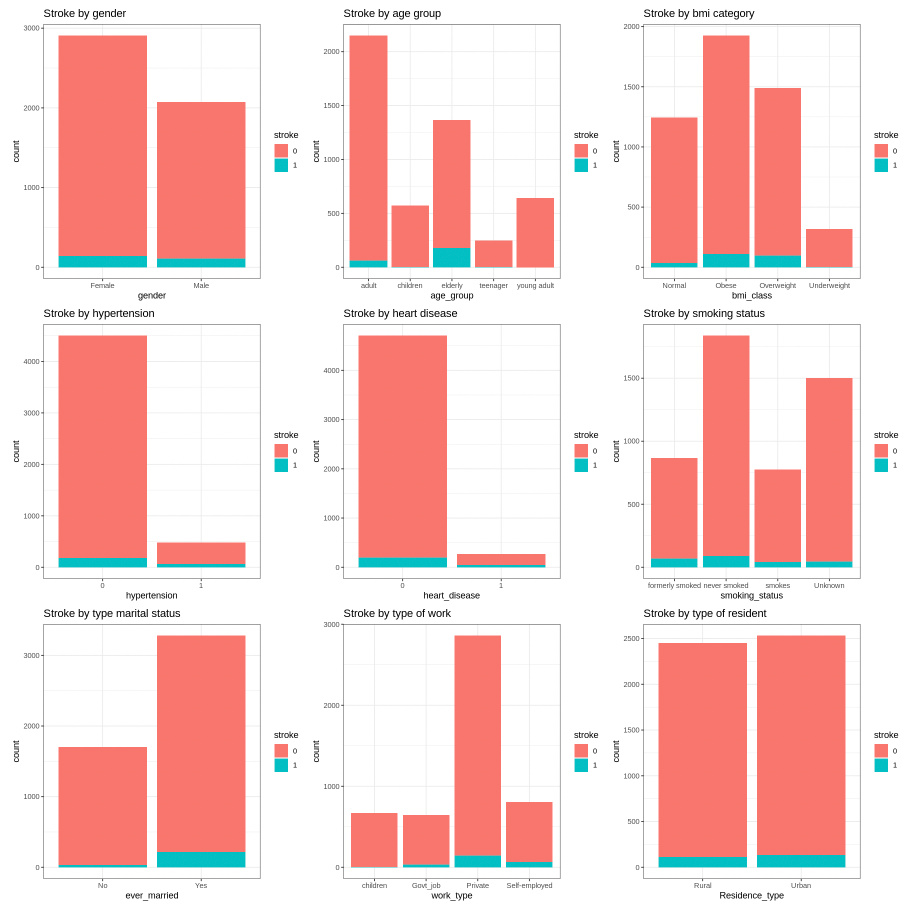
Graphs show the number of patient with and without stroke for each factor.
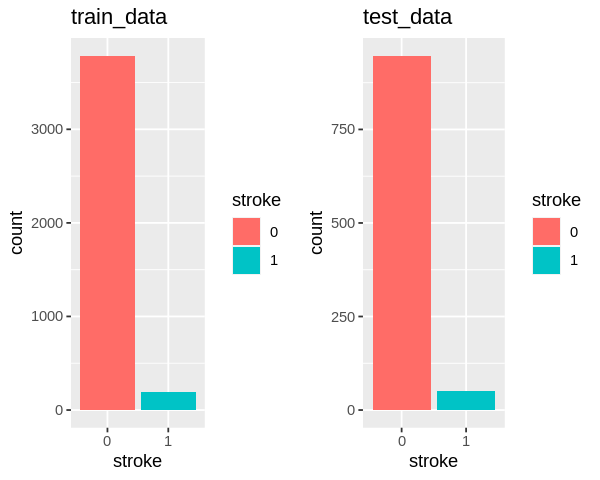
Here we can see the amount of those who have had a stroke is a small portion as compared to those without stroke. In other words, we have imbalanced data with a significant lack of data for patients with stroke.
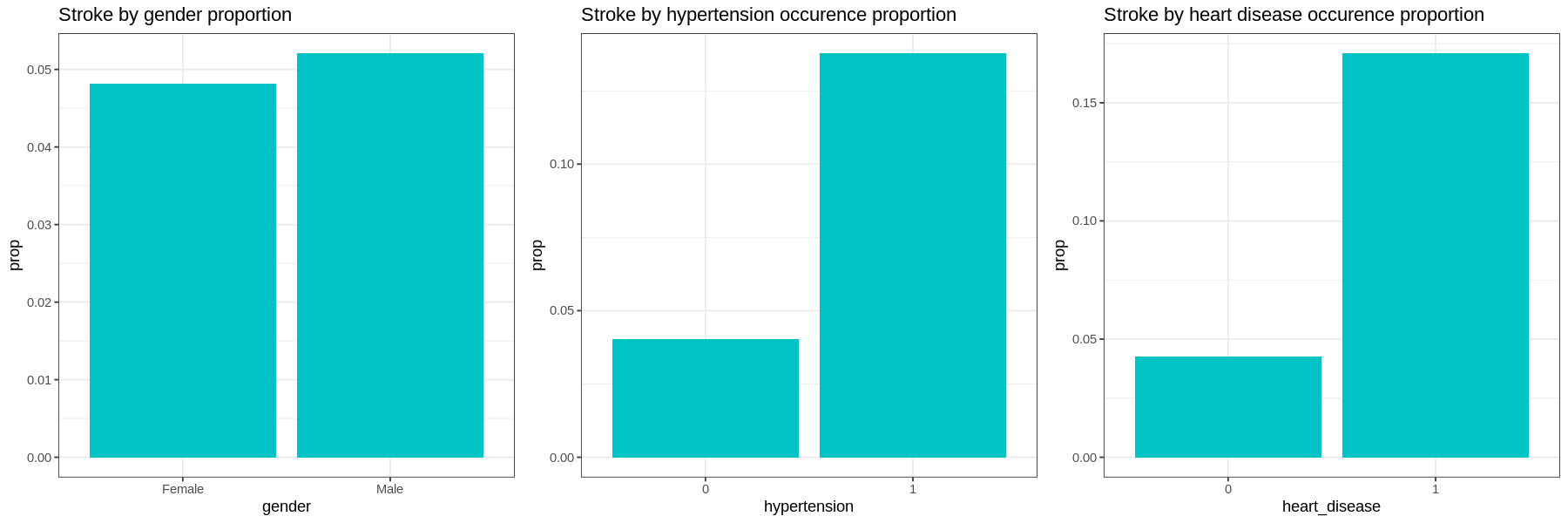
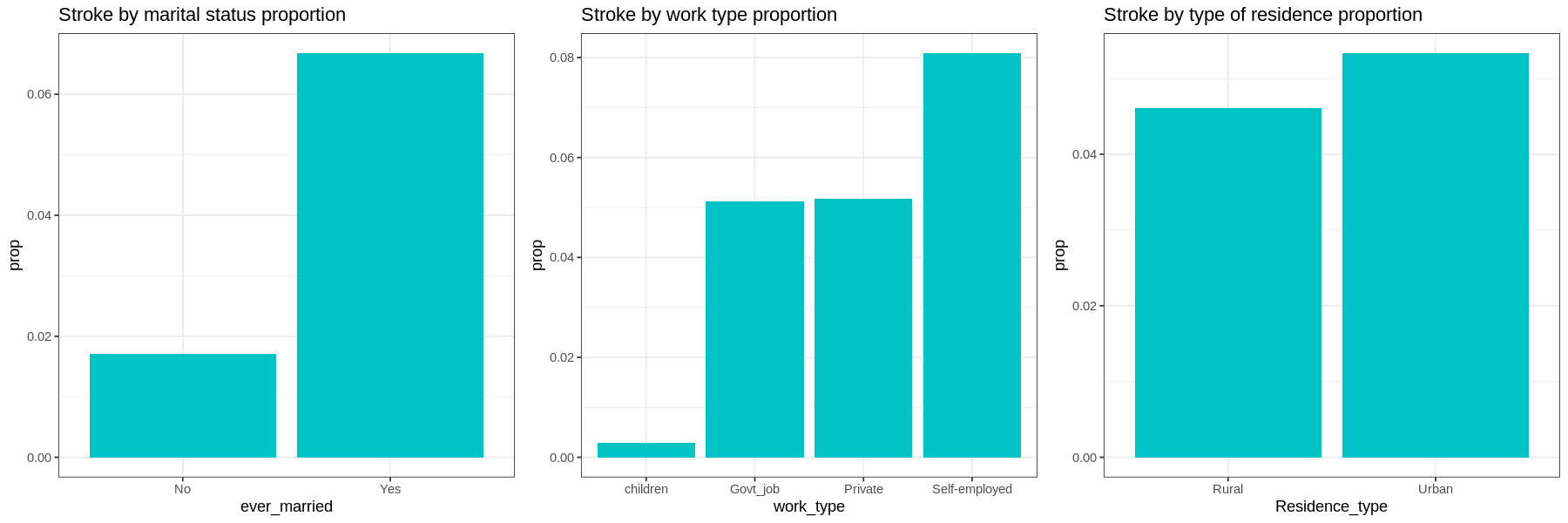
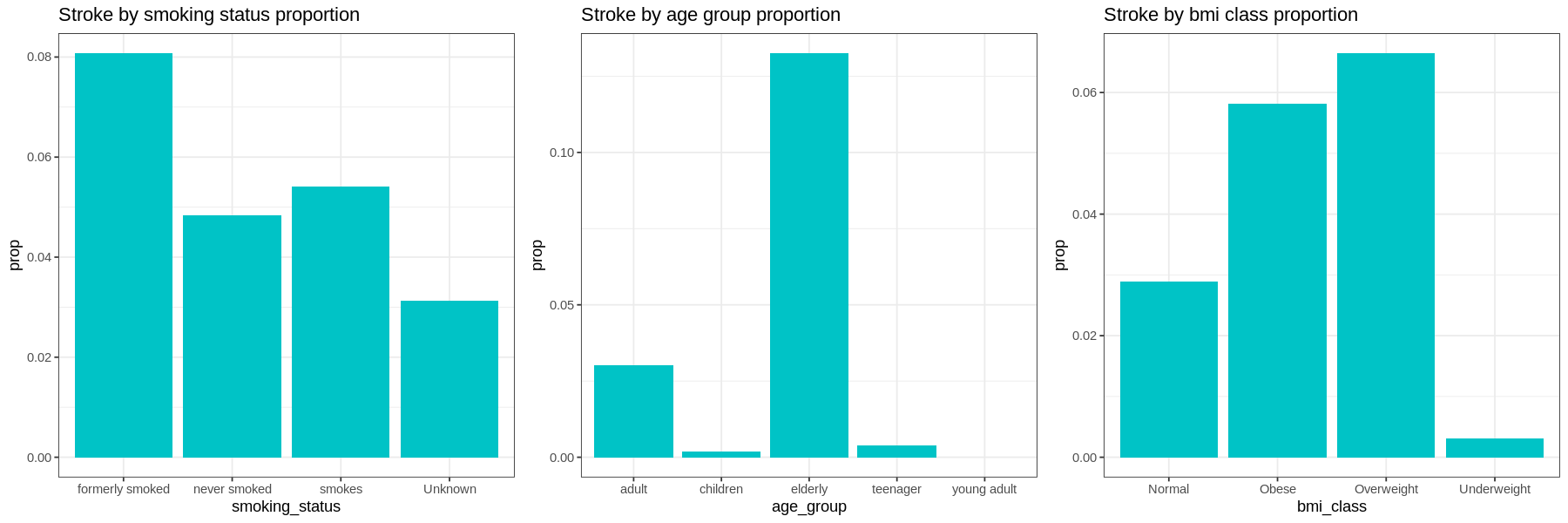
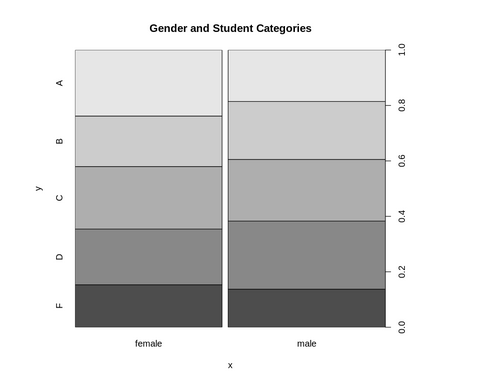
Graphs show the proportion of each factor for patients with stroke:
-
Gender and residence type does not appear to have much difference in occurrences of strokes.
-
Those with hypertension, heart disease, or those who have been married have a much higher proportion of their populations having had a stroke.
-
In terms of work type, Children have very low occurrences of strokes. There is little difference in the proportions of those who work in government and those who work in the private sector. Self-employed have a higher proportion of having strokes than other sectors.
-
Current smokers have a higher proportion of their population having had a stroke than those who have never smoked. Former smokers have a higher occurrence of strokes than current smokers. Those with unknown smoking have a low occurrence of strokes.
-
Elderly at age group has higher proportion of having stroke, followed by adult group. Interestingly, occurence of stroke in children is higher than young adult.
-
The proportion of stroke patients that are overweight and obese are high as compared to other bmi class with overweight slightly higher than obese patient. Those who have strokes very seldom are underweight.
Next, we analyze each factor by age, average glucose level, and bmi.
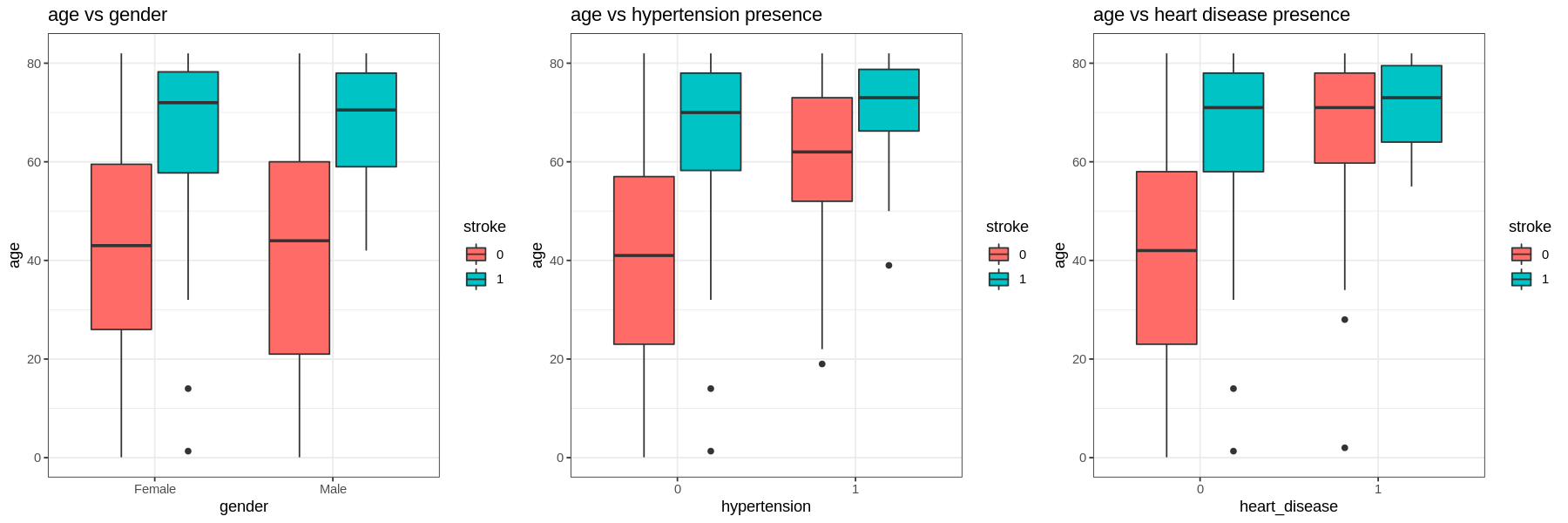
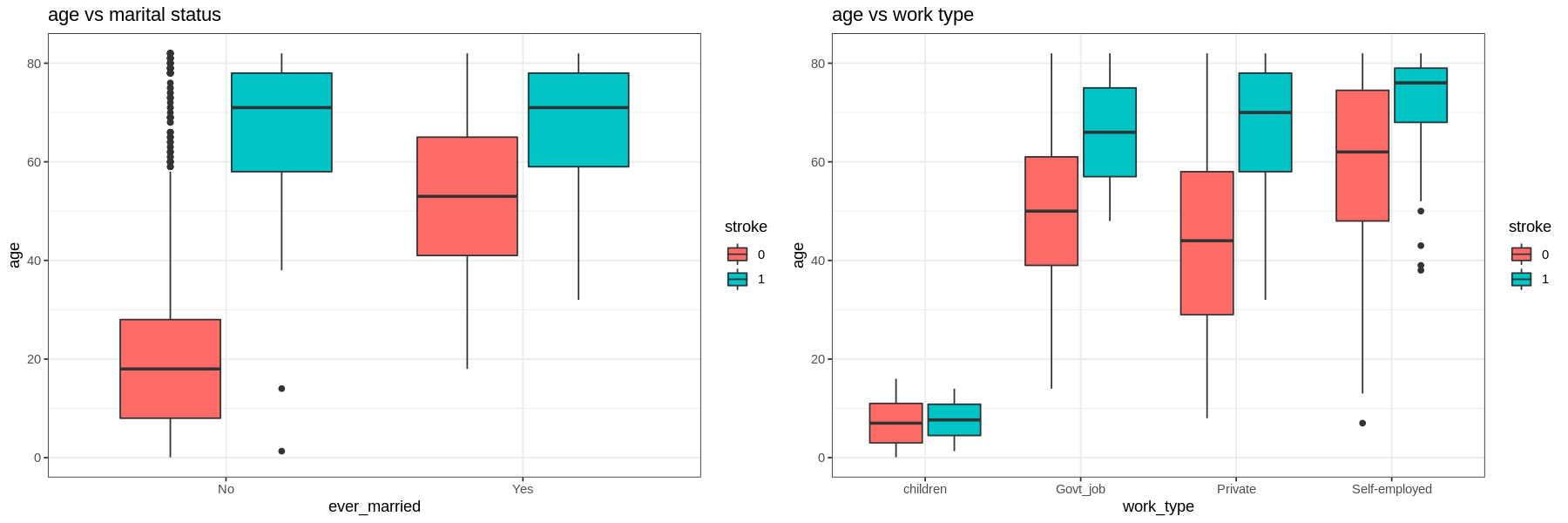
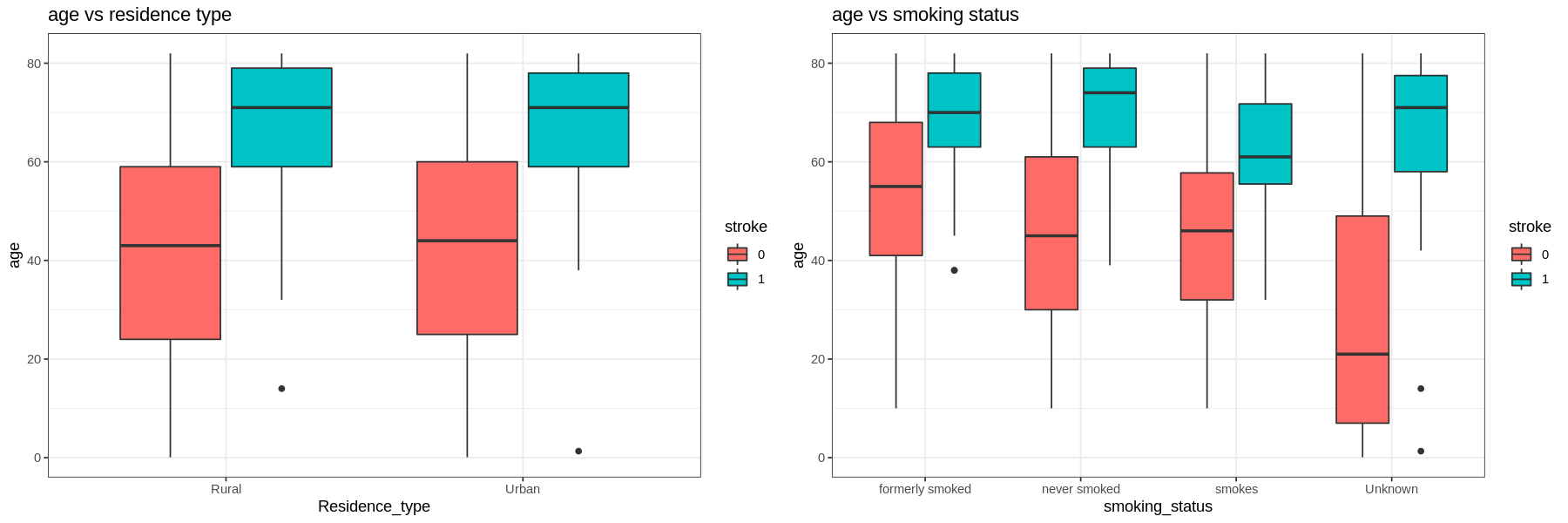
-
For all levels in each factor those who have had a stroke are older.
-
Those with hypertension and heart disease are older than those who do not. Self-employed are also older than the other types of work.
-
Those who had a stroke and smoke are younger than those who quit or never smoked (but still had a stroke).
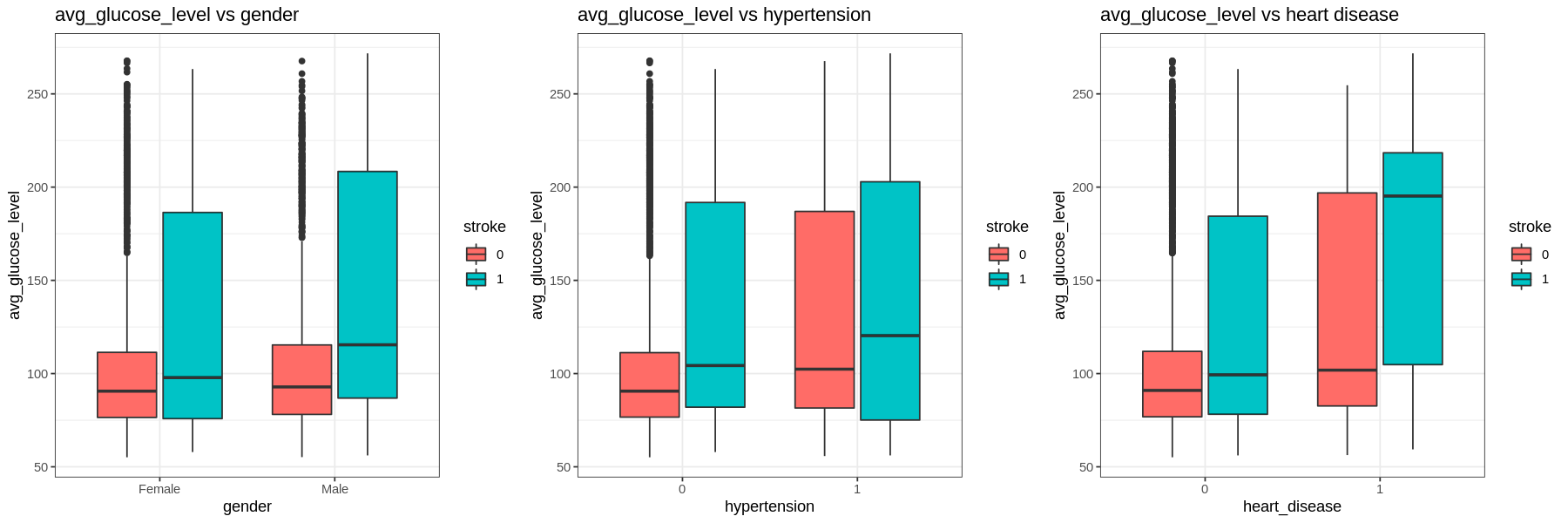
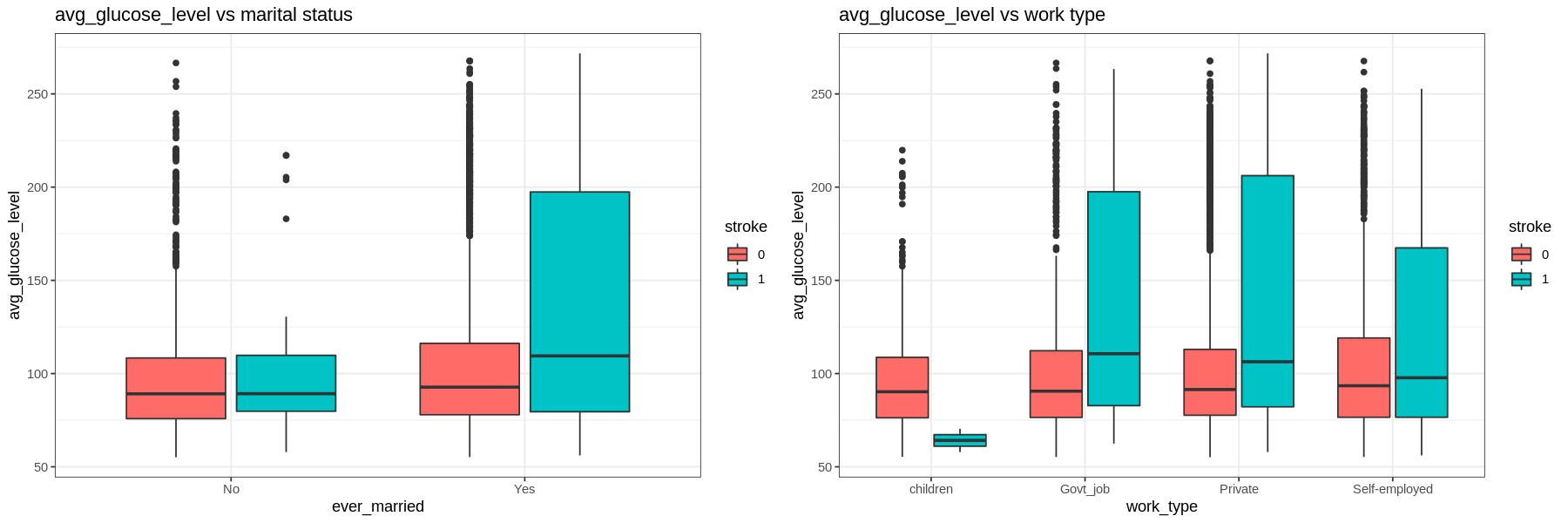
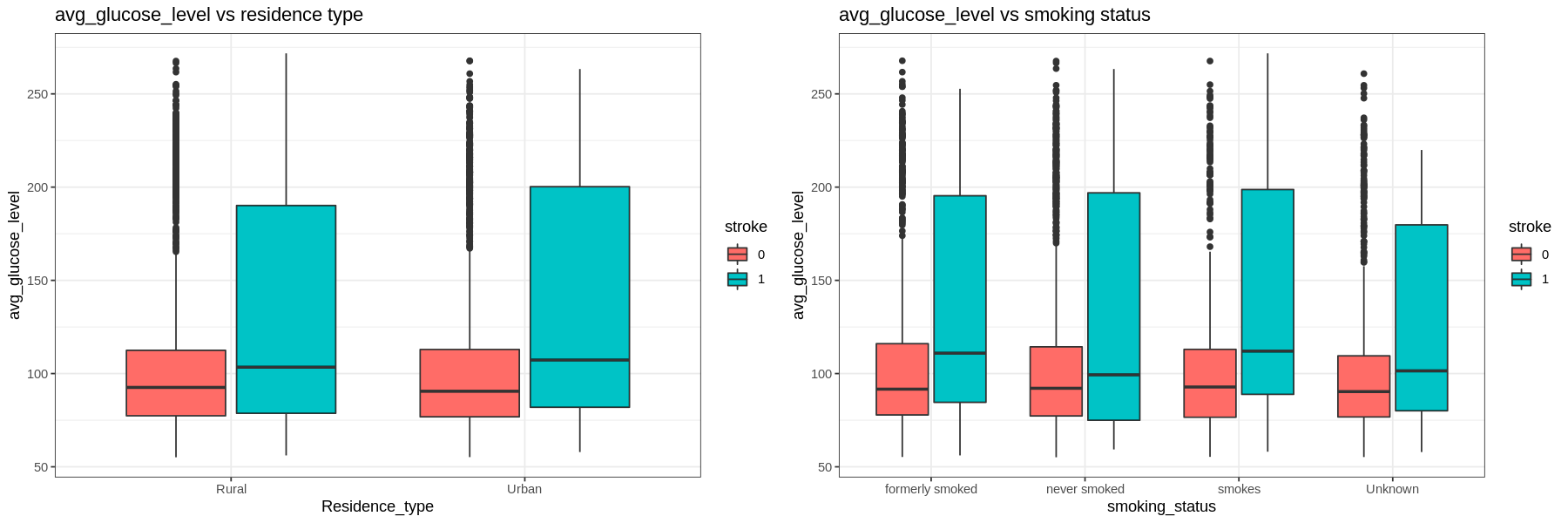
The average glucose level is right skewed.
- The IQR tends to go higher for those who had a stroke. Those with hypertension and heart disease have higher glucose levels regardless of having a stroke or not.
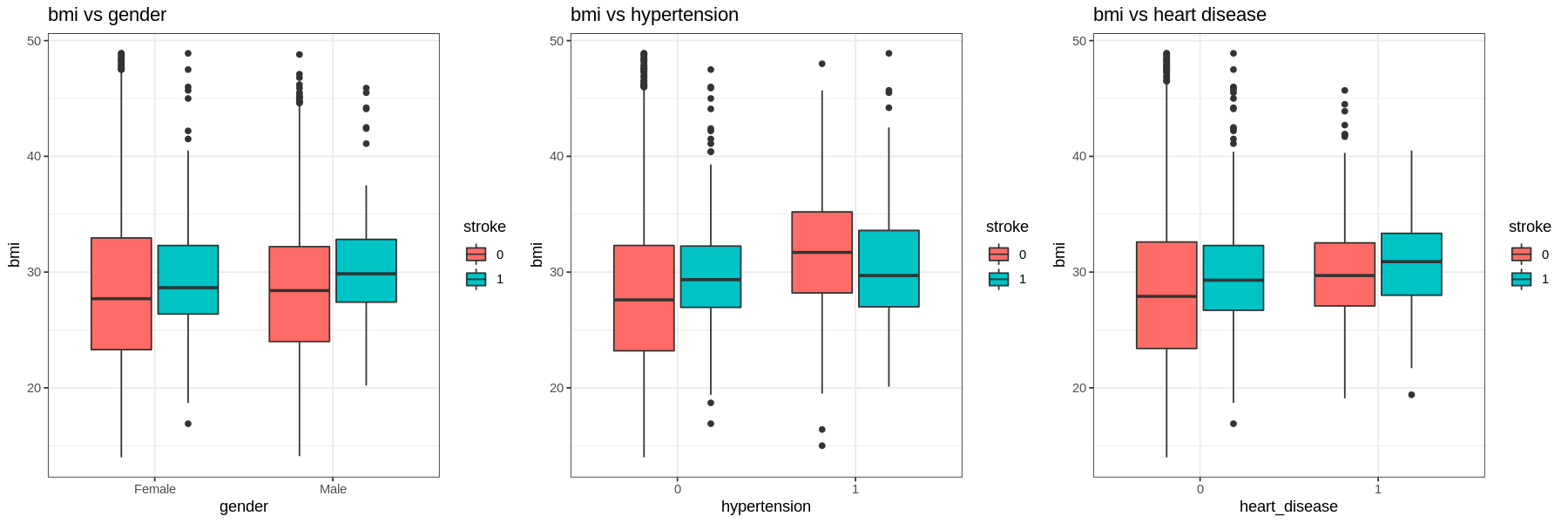
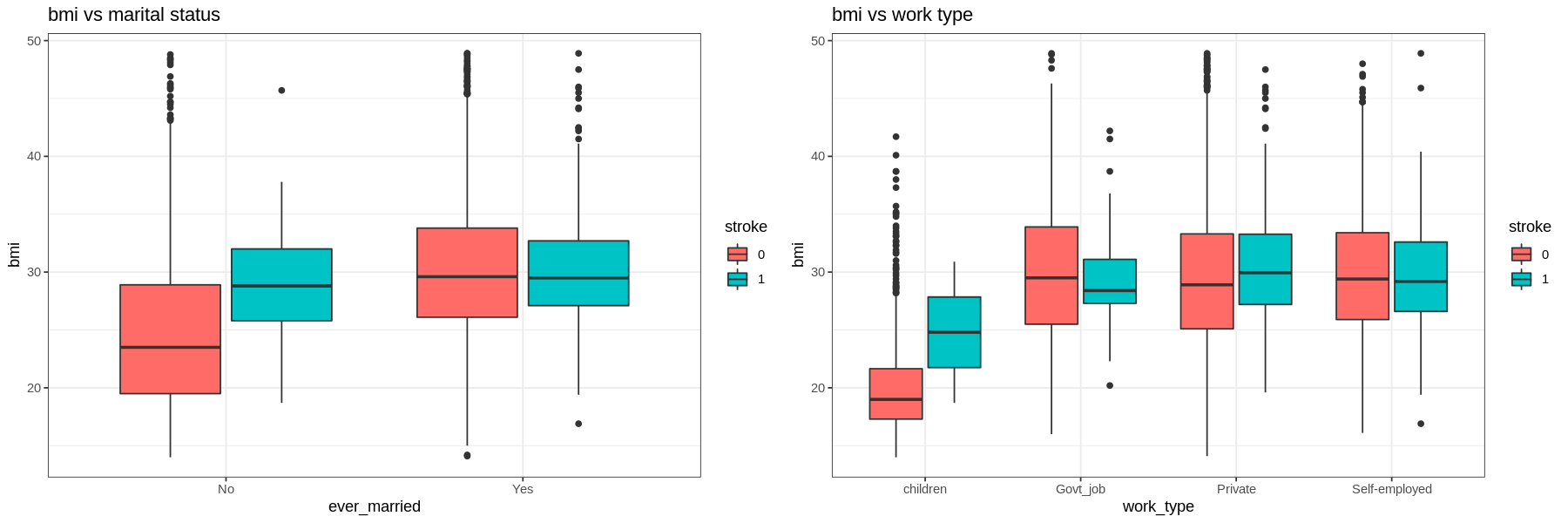
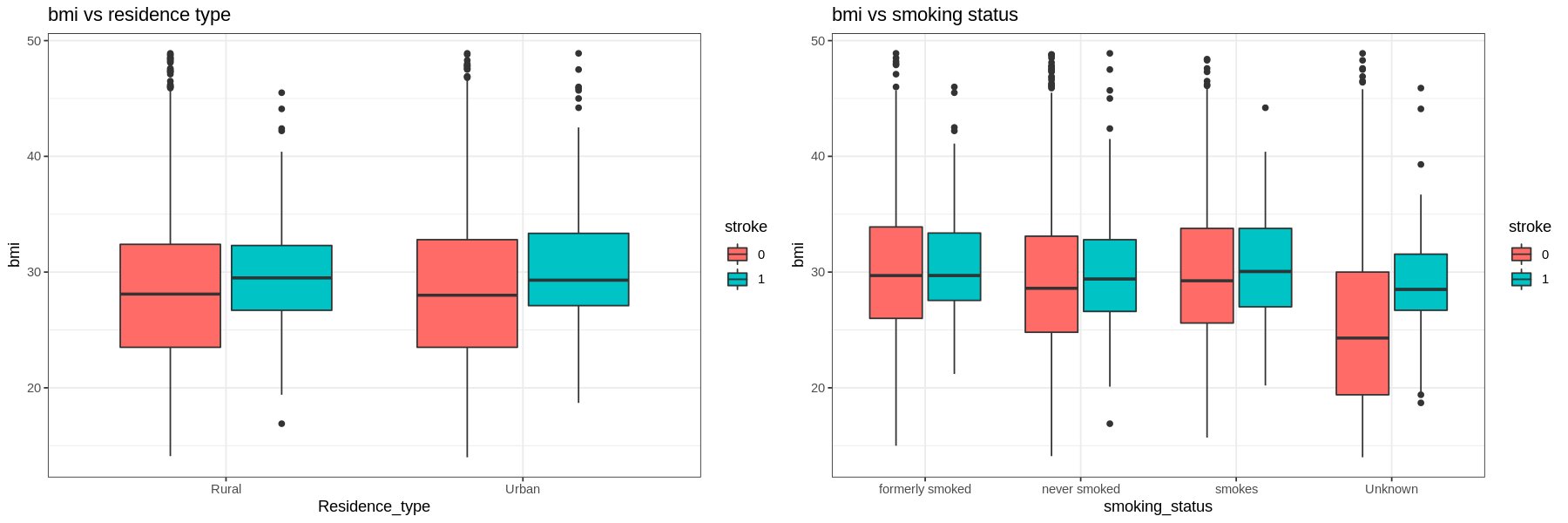
The graphs show that there is not much difference in the BMI of those who had a stroke and those who had not.
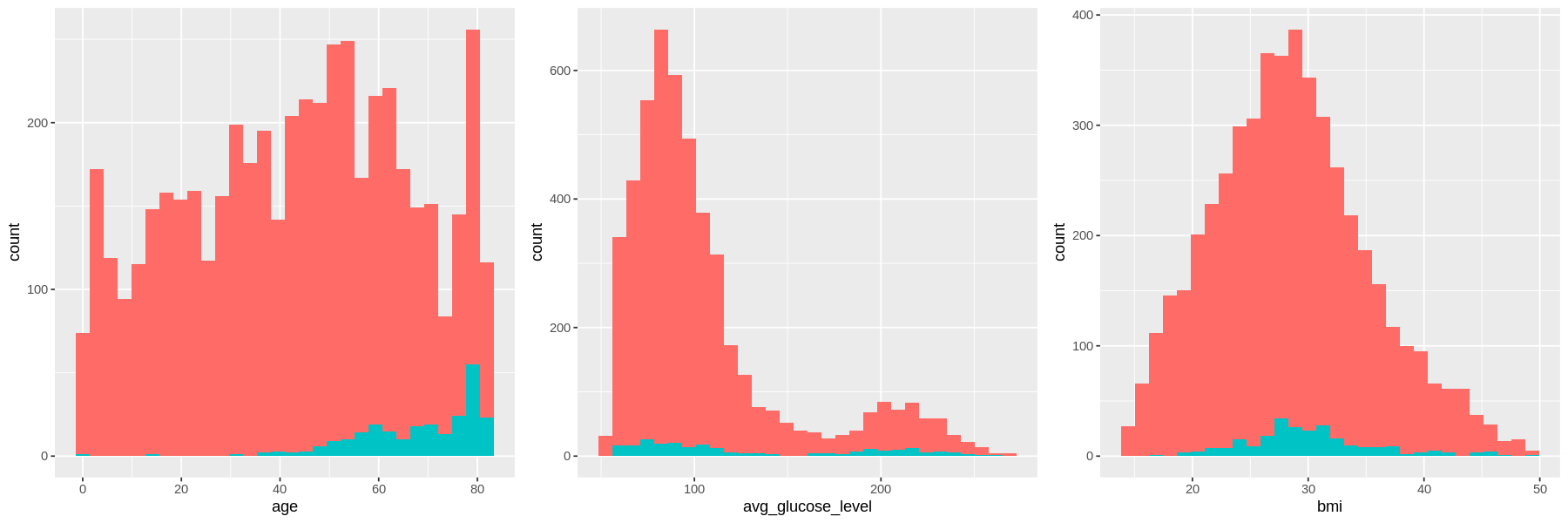
As age increases, the amount of strokes increases.
The distribution for average glucose level is bimodal for both stroke and no stroke populations, with peaks at the same values. However the density of strokes at higher glucose levels is higher than the density of no strokes at the same level.
There is no difference in the distribution of bmi between those who have had a stroke and those who have not..
4. Machine Learning
Split dataset to training and testing set by 80:20

1) Logistic regression


2) Decision tree

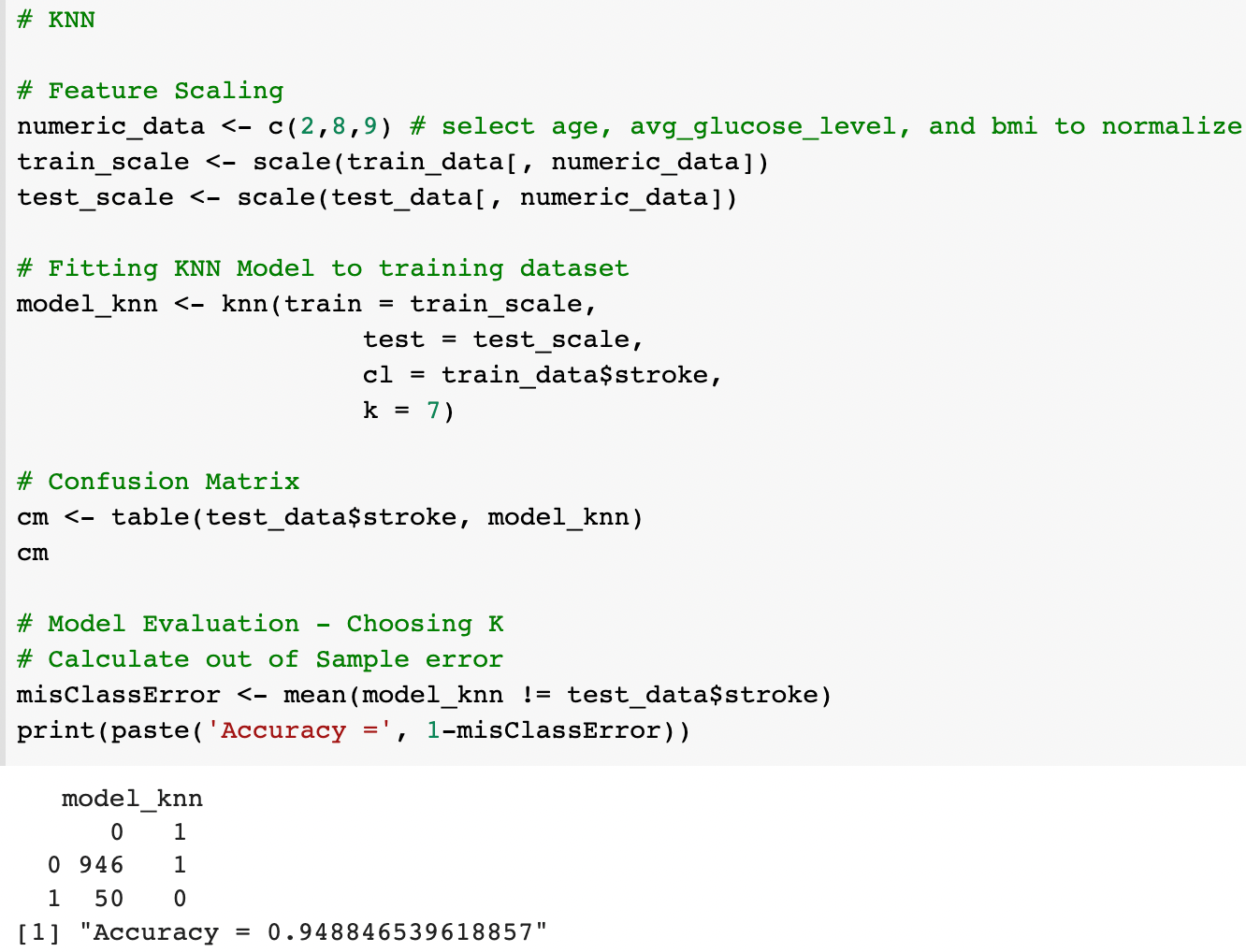
3) KNN




")